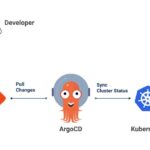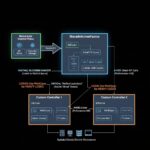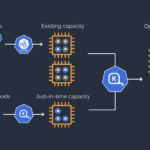
Kubernetes, the industry-standard container orchestration platform, has emerged as a powerful tool for managing AI inference workloads. Its ability to efficiently deploy, scale, and manage complex applications makes it an ideal choice for organizations looking to harness the power of AI. In this blog, we’ll explore five key reasons why Kubernetes is the perfect fit for AI inference.
1. Unmatched Scalability
AI models often require substantial computational resources, especially during peak usage periods. Kubernetes offers robust scaling mechanisms to handle fluctuating demands:
- Horizontal Pod Autoscaler (HPA): Automatically adjusts the number of pod replicas based on metrics like CPU, memory, or custom metrics.
- Vertical Pod Autoscaler (VPA): Dynamically adjusts resource requests and limits for individual pods to optimize resource utilization.
- Cluster Autoscaler (CA): Manages the overall cluster size by adding or removing nodes based on workload requirements.
By leveraging these tools, organizations can ensure optimal resource allocation, cost-efficiency, and high availability for their AI inference services.
2. Efficient Resource Management
Cost-effective utilization of computational resources is crucial for AI inference. Kubernetes provides granular control over resource allocation:
- Pod manifests: Specify exact resource requirements for each pod, including CPU, GPU, and memory.
- Resource limits and requests: Define maximum and minimum resource consumption for containers.
- Autoscaling: Prevent over-provisioning and under-utilization of resources.
By fine-tuning resource allocation, organizations can significantly reduce costs while maintaining performance.
3. Enhanced Performance
Kubernetes offers several features to optimize the performance of AI inference workloads:
- Autoscaling: Dynamically adjust resources based on real-time demand.
- Network optimization: Leverage Kubernetes networking features to minimize latency and maximize throughput.
- Hardware acceleration: Support for GPUs and other accelerators to speed up computations.
By combining these capabilities, organizations can achieve high performance and low latency for their AI inference applications.
4. Portability and Flexibility
AI models often need to be deployed in different environments, such as on-premises, cloud, or edge. Kubernetes provides a consistent platform for deploying and managing these models:
- Containerization: Package AI models and dependencies into portable containers.
- Multi-cloud and hybrid cloud support: Run Kubernetes clusters across different environments.
This flexibility allows organizations to choose the best infrastructure for their needs without compromising model performance.
5. Robust Fault Tolerance
AI inference systems must be highly available to ensure uninterrupted service. Kubernetes offers built-in fault tolerance mechanisms:
- Pod and node failures: Automatic restart and rescheduling of failed components.
- Rolling updates: Deploy new versions of AI models with minimal downtime.
- Health checks: Monitor the health of pods and services.
By leveraging these features, organizations can build resilient AI inference systems that can withstand failures and recover quickly.
Conclusion
Kubernetes is a powerful platform for managing AI inference workloads. Its scalability, resource efficiency, performance optimization, portability, and fault tolerance make it an ideal choice for organizations looking to deploy and scale AI applications effectively. By adopting Kubernetes, organizations can unlock the full potential of their AI models and gain a competitive advantage.
Would you like to delve deeper into a specific aspect of using Kubernetes for AI inference? Explore this Gcore ebook.
Reference to the Article- THENEWSTACK
Follow us for more updates!