
In the world of Kubernetes, where orchestration reigns supreme, keeping track of cluster resources efficiently is crucial for building reliable systems. At Render, engineers encountered real-world challenges while using Kubernetes Informers to monitor Pod scheduling in massive clusters. Informers, those handy tools for streaming resource updates, are incredibly powerful—but as it turns out, they’re also ripe for misuse if you’re not careful. Drawing from experiences shared in a recent Render blog post, this article dives into the essentials of Informers, common pitfalls, and best practices to help you build more robust controllers and operators.
What Are Kubernetes Informers and Why Do They Matter?
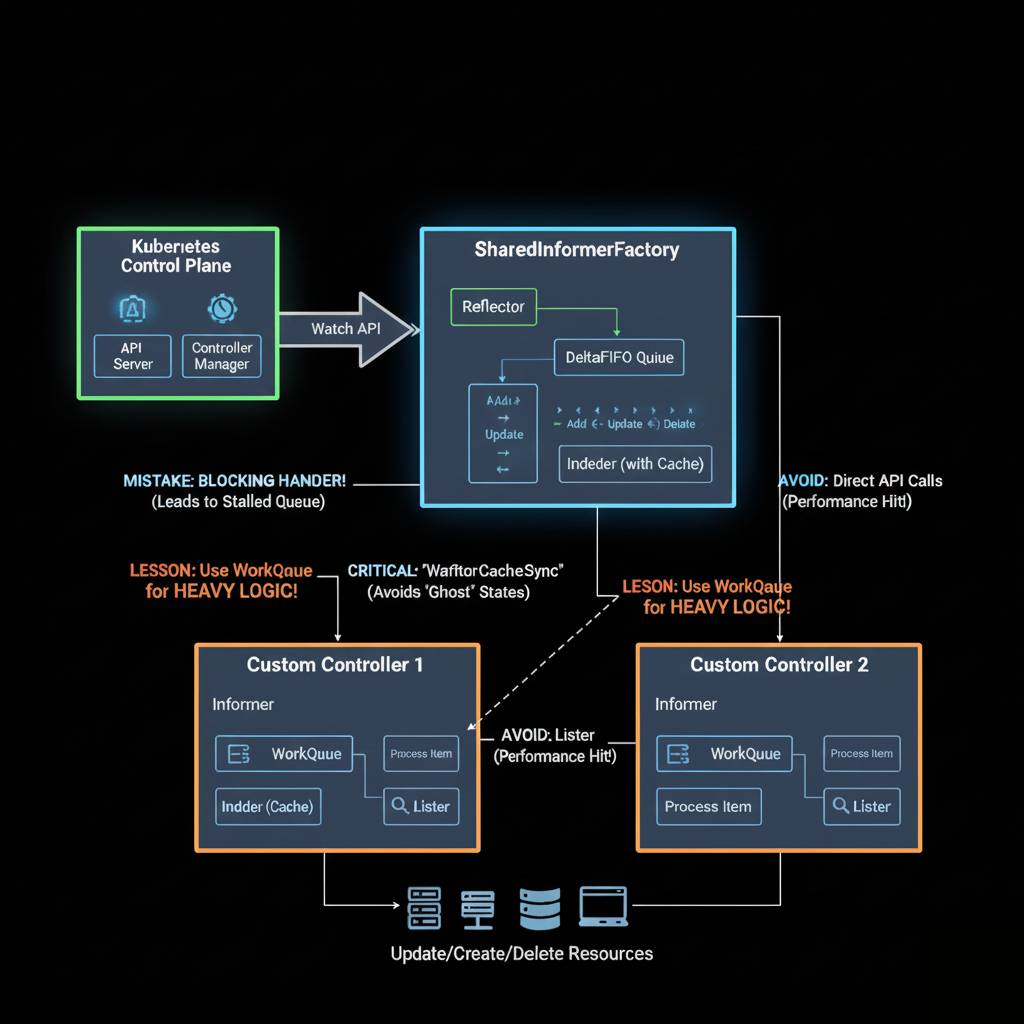
Kubernetes thrives on a principle called reconciliation: an ongoing loop where the system observes the current state, compares it to the desired state, and takes action to bridge the gap. Informers play a starring role here by providing a streamlined way to watch for changes in resources like Pods, Services, or Deployments without constantly polling the API server.
At their core, Informers work like this:
- Initial Sync: They start with a LIST request to fetch all existing resources of a given type. Each one is treated as “new” and added to an in-memory cache while triggering your handler’s AddFunc.
- Ongoing Watch: Next, a WATCH request subscribes to future updates starting from the last known resource version. Creations call AddFunc, deletions trigger DeleteFunc, and modifications hit UpdateFunc with both the old and new object states.
This setup powers everything from core Kubernetes components (like kubelet and kube-controller-manager) to third-party tools such as Knative and Calico. For Render’s use case, Informers helped track Pod-node assignments to optimize compute efficiency in very large clusters. The beauty? They decouple your logic from the API, ensuring eventual consistency without the overhead of manual queries.
But with great power comes great responsibility—especially in production environments with high churn.
Pitfall #1: The Dangers of Edge-Driven Logic in Update Handlers
One of the most tempting mistakes is over-relying on the UpdateFunc. You get both the old and new versions of the object, so why not compare them to detect specific changes and act only when something “interesting” happens? Sounds efficient, right? Wrong.
Kubernetes is designed for level-driven reconciliation, not edge-driven. Here’s why:
- Controllers aren’t always online; they might miss intermediate states during downtime.
- Informers guarantee you’ll eventually see the current state, but not every transition along the way.
- In busy clusters, events can pile up or get dropped, leading to silent failures.
For example, if you’re watching for a boolean flag flipping from false to true, an edge-driven approach (checking if old was false and new is true) might skip action if you only catch the final state. This can wreak havoc during deployments or rollouts.
Pro Tip: Base your logic solely on the new object’s state. If you need to track decisions, annotate the object’s status field. Some teams even modify their handlers to omit the old object entirely, reducing the risk of misuse. Remember the signal processing roots: “Level” means reacting to the steady state, not just the edges of changes.
Pitfall #2: Falling into the OOMLoop Trap
Informers process events serially through Go channels, which is fine for small setups but a nightmare in large clusters. Imagine bootstrapping with a LIST of 100,000 Pods—each one queues up for your OnAdd handler. If that handler blocks (say, due to a slow database write or network call), the queue backs up.
Enter the “OOMLoop”:
- The initial flood fills an unbounded buffer.
- Ongoing WATCH events add more pressure.
- Memory balloons until your Pod gets OOM-killed.
- Kubernetes restarts it, and the cycle repeats.
Render’s team spotted this in metrics: spiking memory, growing backlogs, and frequent restarts. It’s a classic failure mode without proper safeguards.
How to Break Free:
- Keep handlers lightning-fast; offload heavy work to goroutines if needed (though this is a band-aid).
- Embrace Kubernetes’ recommended workqueue.Interface. It adds retries, rate limiting, and metrics, turning your unbounded mess into a controllable system. Yes, it requires more code, but it’s worth it for scalability.
- Monitor queue lengths and processing times to catch issues early.
Pitfall #3: Ignoring Optimization Opportunities
Even if you avoid the above, inefficiency can creep in. Large clusters generate tons of noise—why process it all?
Smart Strategies:
- Leverage the Cache: Instead of querying the API for details, pull from the Informer’s in-memory store. It’s faster and more reliable, especially across regions.
- Filter with Selectors: Use WithTweakListOptions to apply label selectors right at the LIST and WATCH stages. This trims irrelevant resources, easing load on your handlers and network.
- Trim the Fat with Transforms: Hook into SetTransform to strip bulky fields (like verbose environment variables) before caching. Be cautious—this can confuse debugging if overdone.
These tweaks can dramatically reduce resource usage, making your Informers hum in even the biggest environments.
Wrapping Up: Build Resilient Systems with Informers
Kubernetes Informers are a cornerstone of extensible cluster management, but scaling them requires vigilance. Stick to level-driven logic, queue wisely to dodge OOMLoops, and optimize relentlessly. By heeding these lessons from Render’s experiences, you’ll spend less time firefighting and more time innovating.
Whether you’re building custom controllers or enhancing data pipelines, treat Informers as allies—not silver bullets. For deeper dives, check out Kubernetes docs on client-go or experiment in a test cluster. Happy orchestrating!
Follow us for more Updates










